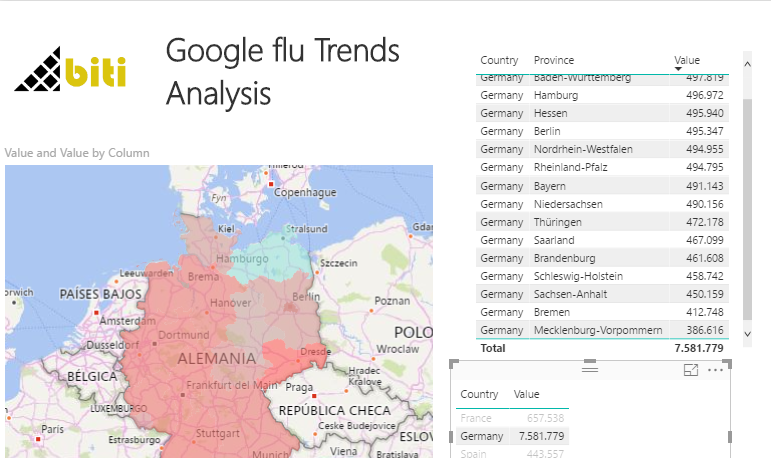
Hoy comenzamos una mini serie de artículos en los que vamos a desarrollar desde cero un proyecto que permitirá cargar, preparar y analizar datos que proceden de procesar “Big Data”, en concreto términos de búsqueda de Google relacionados con la gripe. Esta información está en archivos CSV semiestructurada o no todo lo estructurada que sería deseable.
Antes comencemos explicando estos datos, que usaremos para ilustrar el proceso, de dónde proceden.
En este post:
El proyecto Google Flu Trends Data
La idea de Google Flu trends (Tendencias de la gripe) era buena y bien intencionada. Consistía en analizar los logs de búsquedas, localizando determinados términos o patrones relacionados con la Gripe (Flu), la frecuencia con la que aparecían y la ubicación de donde procedían éstas búsquedas.
A partir de ahí detectar tendencias y hacer predicciones sobre la existencia o localización de brotes virulentos, su ubicación, su virulencia y expansión.
Sí, la idea era buena. Pero falló en las previsiones y, entre otros múltiples factores, su algoritmo se demostró vulnerable a correlaciones accidentales y el proyecto se abandonó. De hecho, se utiliza como ejemplo de los peligros del mal análisis de (Big) Data, lo que no deja de ser algo injusto*.
Los datos a analizar no están estructurados
Pero quedaron los datos y por ahora están a disposición de cualquiera. Son unos archivos de texto con información semiestructurada que vamos a procesar y analizar en PowerBI.
Comenzaremos descargando los archivos de los paises que deseamos analizar, por ejemplo, España, Alemania y Francia. Cada uno de los paises muestra el archivo TXT con los datos que corresponde por regiones: Si pulsamos con el botón derecho del ratón sobre los nombres de cada uno de los paises, elegimos “Guardar destino como” los descargaremos.
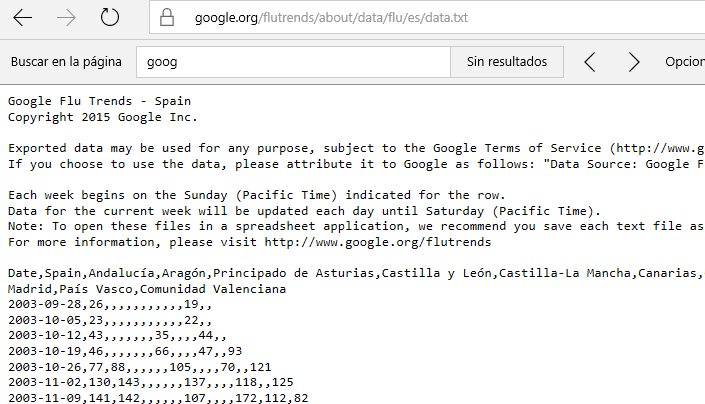
Estos archivos son tipo CSV y contienen la fecha en la primera columna, el total de “casos” de gripe del pais y después los de todas las regiones del mismo. No es un punto de partida que permita un análisis flexible y si sumamos varios archivos, cada uno de ellos tendrá distintas regiones, o sea, columnas, lo que agrava el problema.
Power BI ofrece herramientas para estructurar los datos. Vamos a ello.
Comencemos con Germany
Abre el Query Editor o pulsa el botón “Get Data”.
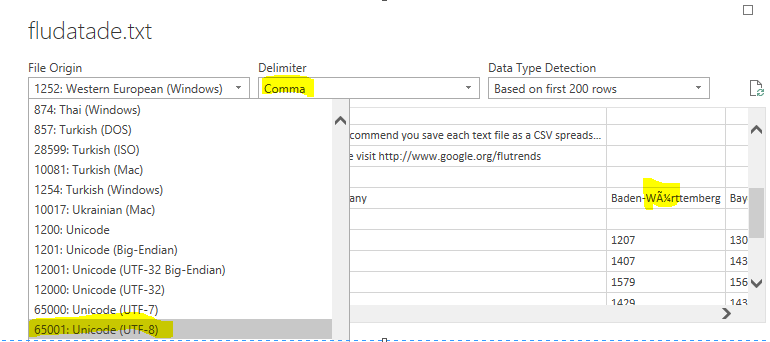
Los datos de Alemania los he guardado en un archivo “flutade.txt” y vamos a cargarlo usando el conector “Text/CSV”. Al igual que el español o francés, es un idioma que contiene caracteres especiales, por ello, cuando se abra el asistente habrá que concretar la codificación adecuada del archivo para que éstos se muestren correctamente. Especificaremos UTF-8 en File Origin. El separador de columnas “Coma”.
Una vez cargado el archivo eliminaremos las primeras filas del mismo (“Remove top rows”), en este caso 11, y promoveremos la primera como encabezado de la tabla .
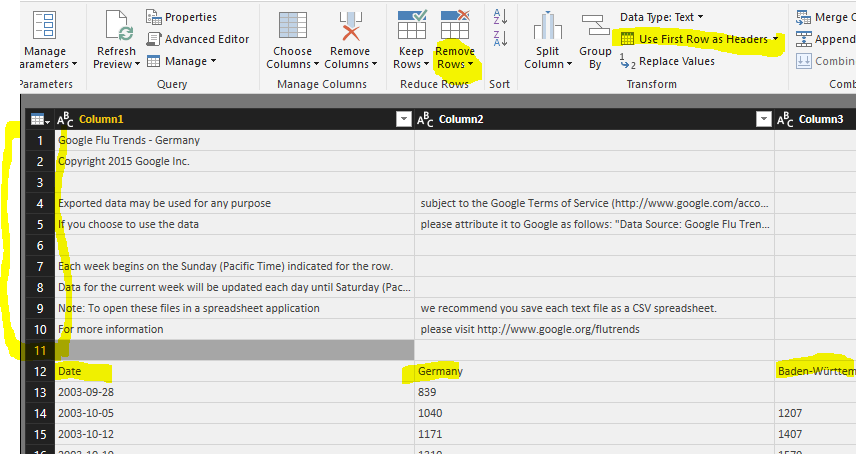
La tabla quedará así:

A continuación, vamos a seleccionar las columnas desde la número 3 hasta el final (las “regiones”). La finalidad es hacer una trasposición y convertirlas a filas (Unpivot columns). Esto permitirá realizar análisis mucho más flexible que la estructura actual.
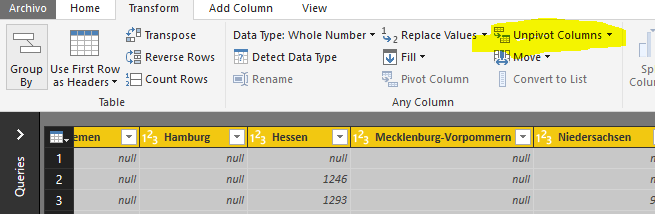
Quedando como se muestra.
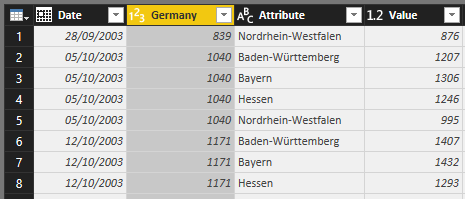
Observa que los valores vacios o null se han ignorado en la trasposición. Pero si no fuese así siempre podrás filtrarlos:
![]()
Nos asegurarnos de que PowerBI ha detectado los tipos de dato de cada columna correctamente y si no, que no ha sido el caso, aprovechamos para ajustarlo.
Aprovecharemos para añadir una nueva columna (Custom Column) que almacenará el país como valor fijo:
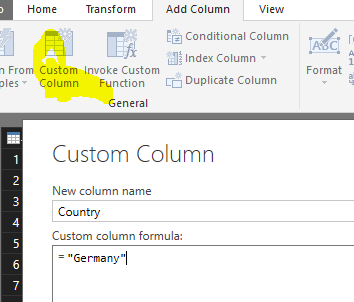

También eliminaremos la columna “Germany”, que guarda el total de cada fila antes de la trasposición y este valor deja de tener sentido, pues se calculará dinámicamente en los reports.
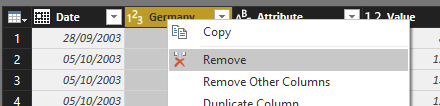
La tabla finalmente quedará como se muestra:
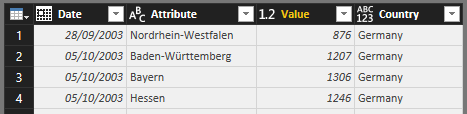
Cargamos el resto de archivos: Francia y España
Ahora habrá que hacer lo mismo con los otros 2 archivos. Para ello podemos repetir los pasos indicados con la salvedad de poner el nombre del país que corresponda en la columna agregada “Country”.
¿Podemos copiar los pasos?
Sí, aunque en este caso no va a resultar “rentable”, pero creo que es interesante mencionarla.
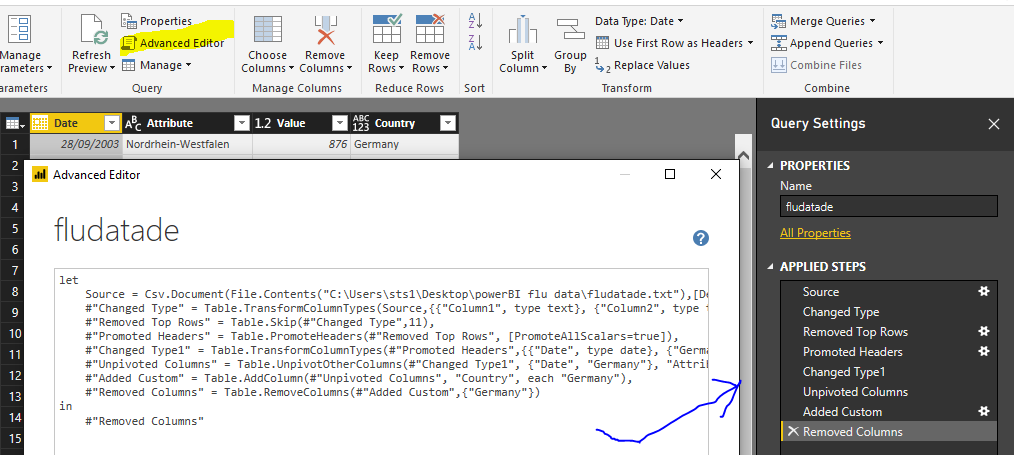
Todos los pasos que se han ido realizando anteriormente se listan en el panel derecho (Applied Steps). Sería genial poder copiar la lista de pasos y pegarlos como nuevos en otro archivo… Y, aunque no va ser tan sencillo como esto, por ahí va la idea. Si queremos ver el código generado por cada uno de estos pasos podemos verlo en el “Advanced editor”:
Podemos copiar este código, ir al nuevo archivo agregado, ver su código en el editor avanzado, y reemplazar selectivamente con el código copiado. En este caso, lo cierto es que requiere hacer bastantes ajustes en el código para adaptarlo convenientemente al nuevo archivo, por lo que desecharemos la idea.
Pero ya conoces una nueva posibilidad, que siempre viene bien.
Fusionar todo en una tabla
Después de procesar los archivos que hayas decidido agregar tendremos varias tablas con las mismas columnas, mismo tipo de datos y vamos a fusionarlas en una que será la que analicemos.
Realizaremos un “Append Queries as New”.
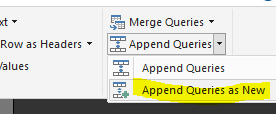
La finalidad es seleccionar las tablas que queremos convertir en una nueva:
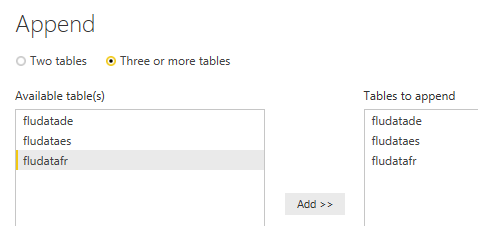
Tras pasar a la lista de la derecha las tablas a fusionar y pulsar ok aparecerá una nueva tabla “Append1”. Yo la llamaré “GoogleFluEU”. También podemos poner nombres de columna más adecuados.
Y hemos terminado con el Query Editor. Ya podemos finalizar el proceso de importación-conversión y pasar a la parte de análisis de Power BI. Pulsa Close&Apply.
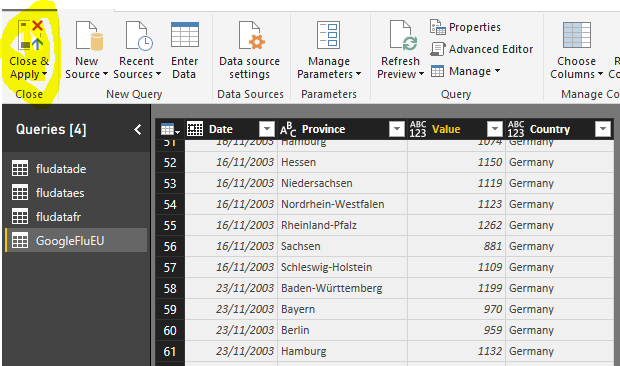
En un próximo artículo prepararemos los datos y procederemos a confeccionar un pequeño Dashboard para su análisis.
*En este artículo de Wired.com encontrarás más detalles sobre las causas del fracaso del proyecto Google Flu Trends.

Apasionado de las tecnologías de análisis de datos y Business Intelligence, y con larga experiencia en el uso de las mismas en empresas de todos los sectores, tamaños, y proyectos de diversa complejidad, en los cuales disfruto creando, planteando y desarrollando soluciones.
Tengo una curiosidad insaciable y demasiadas aficiones, entre ellas tocar el bajo con mi grupo.
Un comentario en «Analizando Big Data: Archivos semiestructurados en PowerBI»